
Song Segmentation method for a contiguous playlist
Introduction
For artists, one of the most important problems is to know when their music is reproduced, in order to get royalties from it.
This article presents a method, which uses Hidden Markov Models (HMM), for understanding by how many songs a specific audio stream is composed of. In Machine Learning we call this particular procedure “segmentation”. The segmentation operation is then defined as a generic operation where a particular object is taken (i.e. an image) and its various components are divided (i.e. foreground and background). In our case the expected output of the operation is a set of number pairs, where the first one is the beginning of the song and the second one is the end of the song.
Statement of the problem for song segmentation
All the operations that can be performed on an audio stream are studied and related to a new interesting subject called Music Information Retrieval. This field is very young, and due to this reason, is not standardized. Therefore, there are no widespread solutions accepted by the scientific and industrial community, and so the reader is encouraged in finding other resources and contributes to the knowledge of the community.
The audio is generally represented as a temporal series, or rather a series of numbers which are the result of some functions or related to a temporal evolution of a system. Anyway, even if the representation of audio as a temporal series could mislead people thinking that there is a description of it, there exists no general equation to describe it, and this is a fundamental consideration of this article.
Due to the fact that there is no equation to describe the audio, it means that I cannot define a system out of the equation, for this reason the dynamic evolution of an audio signal is a stochastic problem. The study of stochastic systems is a branch of math where it is supposed that we can describe a particular phenomena, but we cannot assume to have a system (and then a dynamic), so we must use other methods, like probabilistic ones, to estimate the dynamic evolution of the system.
One method that can be derived for the description of a stochastic system, is the Hidden Markov Model (HMM).
The Hidden Markov Model has a not very user-friendly mathematical description, and is not the central topic of this article, so a reference to Wikipedia is left to start understanding in a very simple way this object if interested.
To make everything simpler, you can imagine the HMM as a “probabilistic FSM”, where we cannot know the current states, but we can estimate it in a probabilistic way. This FSM has the states that are supposed a priori, or rather, the engineer must choose a set of states which thinks suits the problem. Once the states and their transition order is defined, we must provide a training set, out of which the HMM will be trained. Training an HMM means assigning to every transition a probability, and to every state a probability of emission for every feature chosen to represent the audio signal. This makes the problem completely stochastic in its evolution, and the emissions of every state are used to estimate in which states we are.
Before moving on to the next chapter, let me just briefly introduce how the HMM is built. We have two states, “same song” and “changing song”, the first one should be the state where we are for most of the time, the transition to the second one is triggered for a small time when the song is changing. Here below an image of the HMM:
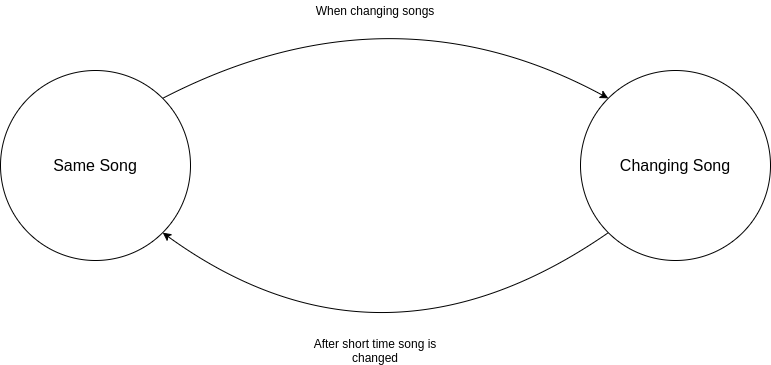
Figure 1: HMM used
Now that we have introduced the audio representation and the object we use to segment, we explain how to use the two together.
Training method and objectives for song segmentation
The goal of the model is to segment the various songs, or rather produce a list of timings that represent the beginning and the end of every song, as previously said.
The problem of segmentation then can be reduced to understanding when the difference between the features of two temporal windows occurs.
So a song changes when the variance of the features extracted between two temporal windows analyzed is high.
The objective is then to make the HMM understand that it must change the state from “same song” to “changing song” for little time when the features extracted have great variance respect to the previous ones. So the following training method has been followed:
- A specific number of songs were chosen, with their genres to be the most heterogeneous possible, because it is possible that the feature extracted from the audio signal could be similar if they belong to the same genre.
- From songs chosen randomly, it was created a unique music file with all the songs concatenated.
- It was created a csv file where it was annotated the timings which compose the unique music files on the first two columns (the begin and the end of every song which compose the stream) and on the third one the HMM states which we want to relate. The annotation follows these two rule: first one is that the rows were divided in two categories one after the other, to make the library understand the transition between states, second one is the fact that the second type of row (“changing song”), starts 0.5s before the ending of the previous song and lasts for 1s of the following song, to make the machine understand that “changing song” is a temporary state used just for reporting a change in the playlist.
Output and Accuracy of song segmentation method
The overall accuracy obtained by the method proposed is 97%, with worst case 95% and best case 99% over 10 executions, each of them of a 3 minutes stream composed by 6 songs of 30 seconds.
Below a plot of one of the outputs:
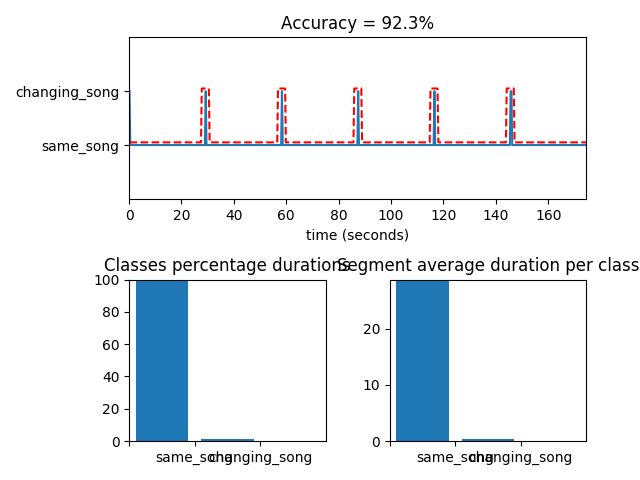
The blue line shows the time evolution of the playlist passed in input to the HMM with respect to its two states. The spikes represent when there must be a change of state due an actual change of song in the playlist.
The red line is the fit made by the HMM.
As it can be seen the model is quite accurate because every time it changed state was in proximity of an actual change of song, so it was avoided the worst possible situation which would have been the fact that the HMM reports a ghost change of state. Anyway the accuracy is not 100% (which is very difficult to obtain, or impossible) because the HMM enlightens a bigger temporal window for the change of song. This can be seen because the red line does not fit perfectly the blue spike, but has a little bigger amplitude.
Conclusions
First of all thanks to Ettore Cinquetti, I developed this project with him, and his suggestions were fundamental.
In this article we review a little bit what can be a possible method to segment songs in a playlist, and introduced the Hidden Markov Model as a possible approach to perform it.
The average accuracy was satisfactory given the fact that we used a non neural method with a white-box extracted feature approach.
I hope that the reader had a good time reading the article.
Best Regards and enjoy your acceleration

Ciao Enrico, ti faccio una domanda, hai fatto queste prove con una playlist continua di brani che si uniscono più o meno bruscamente, oppure con un effetto fade-in fade-out? Hai provato una playlist per DJ di un programma radiofonico, in cui tutte le canzoni si uniscono in un mix, con il DJ che eventualmente parla sopra il mix? Migliori saluti!
Ciao Daniel! Grazie per il commento 🙂 I test che abbiamo fatto erano presi da registrazioni radiofoniche reali di diversi programmi radiofonici con un vocalist che “ogni tanto” parlava, quindi possiamo dire che il metodo funziona sia con mix in fade-in / fade-out sia con tecniche di mix più complesse