
Versal ACAP discovering: the new Xilinx technology
Introduction
This article is aimed to present in a comprehensible way the new Versal ACAP device developed by Xilinx Inc.
Let’s start from the signature, what does ACAP mean? ACAP stands for Adaptive Computing Acceleration Platform, which enlightens the actual goal achieved by Xilinx with this new generation of platform, or rather to create a fully software programmable platform.
The new Versal generation, in fact, with the support of the new Vitis IDE, allows every type of programmer, from Data Scientists to Hardware Engineers, to deploy their applications.
The new Versal Architecture is based on a 7nm production process, so it overcomes the past 16nm UltraScale+ by halving the transistors dimension.
We said previously that Versal ACAP is for everyone, but what is the reason? What changes in the beneath architectural implementation? We will cover in the next paragraphs why Versal ACAP is a market game-changer.
Versal Architecture
We now detail the new Versal ACAP architecture:
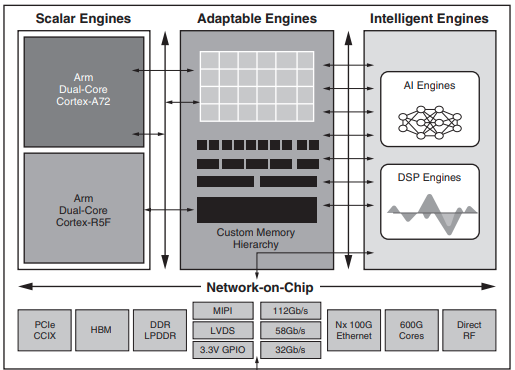
As it can be seen from the above image, we have two new features with respect to the previous FPGA generations:
- The integration of a new component, the AI Engine cores, a set of Intelligent Engines which are optimized for 5G communication and Artificial Intelligence, delivering performances in the order of the tenth of TeraOperation/s with deterministic latency.
- The new Network On Chip (NoC) connection between the components, which allows a communication bandwidth in the order of TeraBytes/s.
The system has also the features of previous generations:
- Scalar Engines: This is the Processing System portion of the chip, where it is possible to deploy host applications.
- Adaptable Engines: This is the Programmable Logic portion of the chip, which can be freely reprogrammed by the user to deploy every type of application to be accelerated, with deterministic latency.
- Intelligent Engines: This part of the chip hosts the new AI Engine cores for vector computing applications and DSP Engines, with the revolutionary native support of single precision floating point type, allowing users to accelerate every application which eventually needs high data precision and deterministic latency.
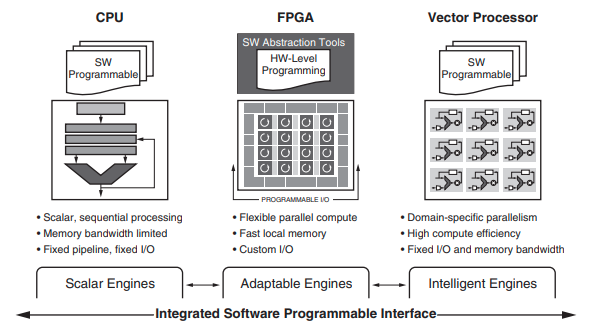
To summarise, the new Versal ACAP allows users to deploy a wide range of applications which can be accelerated with deterministic latency. Below a picture to provide some more clarifications:
AI Engines Cores
In the previous chapter we introduced the new vector optimized Intelligent Engines provided by the new Versal ACAP, which could be software programmed.
We now explain briefly the new AI Engines cores architecture and why they are optimized for Artificial Intelligence and 5G.
Artificial Intelligence and 5G have two main necessities:
- There is the need of a huge computational power to deliver appropriate performances for the real-world application, where we need both deterministic performances and low latency.
- There is the need of a high performance data transfer, where a lot of data can be pumped into the compute units (data-intensive applications).
The AI Engine cores are the solution for both of the two previous points:
- As previously said they deliver deterministic performances in the order of the tenth of TeraOperations/s, i.e. you can infer a neural network in the order of microseconds, even in floating point.
- The Network on Chip is capable of feeding data into the AI Engines in the order of TeraBytes/s.
To deliver such impressive performances, the AI Engines cores support SIMD (Single Instruction Multiple Data) instructions, which computes a vector of data in at most one clock cycle, which actually computes with a single instruction multiple data coming from the NoC.
We shall now show a picture of how the AI Engines are placed in the chip:
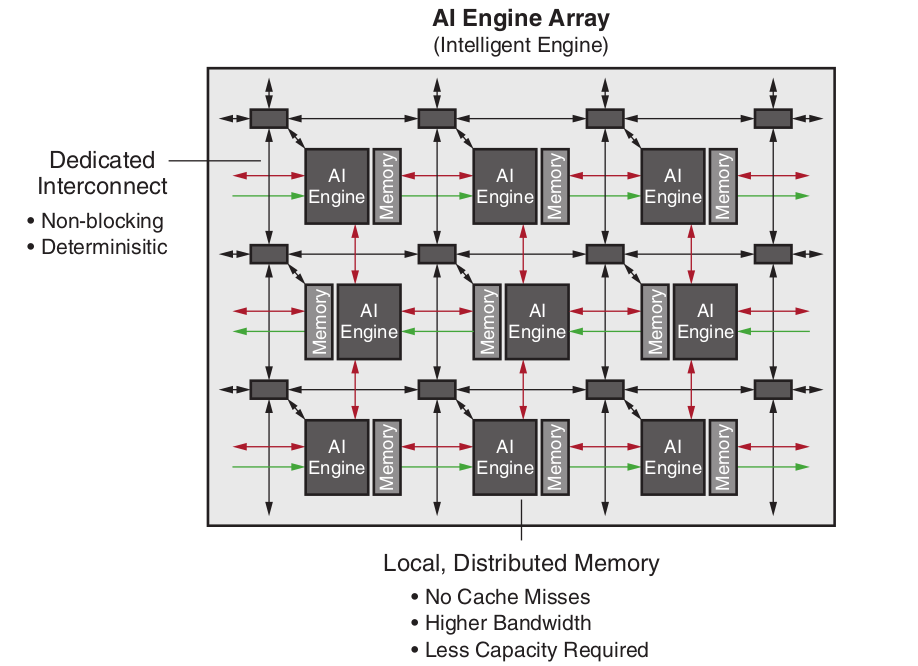
The AI Engines cores are placed with a matrix structure, where ideally every tile represents a cell, interconnected with its neighbors.
As it can be seen from the picture, the tiles do not have memory coherence, but every tile has its own local memory (which can be shared with other nearby tiles). This choice has been deliberately taken by Xilinx to speed-up the computation of the tiles.
Summary
We have presented the new Versal ACAP, with a little insight into every component along its features.
We have also shown why Versal ACAP could be adapted for every application with its 3 different types of computation method.
In the next articles we will cover more specifically the new AI Engine cores.
Thank you for your attention.
Enjoy your acceleration
